library(here)
library(tidyverse)
library(countrycode)
library(huxtable)Charger les principaux packages
Récupérer les données
Astuce
Pour récupérer des données sur les pays européens, le package eurostat est votre ami. Parcourez le catalogue avec la fonction eurostat::get_eurostat_toc()
crim_just_job_path = here("data", "crim_just_job.rds")eurostat::get_eurostat("crim_just_job", type = "label", cache_dir = here("data")) |>
write_rds(crim_just_job_path)crim_just_job = read_rds(crim_just_job_path)Une rapide inspection :
glimpse(crim_just_job)Rows: 9,376
Columns: 6
$ isco08 <chr> "Professional judges", "Professional judges", "Professional jud…
$ sex <chr> "Females", "Females", "Females", "Females", "Females", "Females…
$ unit <chr> "Number", "Number", "Number", "Number", "Number", "Number", "Nu…
$ geo <chr> "Albania", "Austria", "Bosnia and Herzegovina", "Bulgaria", "Cy…
$ time <date> 2021-01-01, 2021-01-01, 2021-01-01, 2021-01-01, 2021-01-01, 20…
$ values <dbl> 170, 216, 761, 1450, 71, 2080, 1750, 650, 1204, 1887, 71, 28, 4…Les recoder
Astuce
Dès que vous devez manipuler des noms et codes de pays, pensez au package countrycode.
police_europe = crim_just_job |>
pivot_wider(names_from = c(sex, isco08, unit),
values_from = "values",
names_repair = janitor::make_clean_names) |>
complete(geo, time) |>
mutate(geo = if_else(geo %in% c("Scotland", "England and Wales", "Northern Ireland (UK)"),
"United Kingdom", geo)) |>
summarise(across(ends_with("number"), ~ sum(.x, na.rm = F)), .by = c(geo, time)) |>
mutate(geo = str_replace(geo, "Türkiye", "Turkey"),
geo = if_else(str_detect(geo, "Germany"), "Germany", geo),
geo = if_else(str_detect(geo, "Kosovo"), "Republic of Kosovo", geo),
year = year(time),
wb = countrycode(geo, origin = "country.name", destination = "wb")) |>
select(wb, year, total_police_officers_number)On manque de données pour certaines années, pour certains pays :
questionr::freq.na(police_europe) missing %
total_police_officers_number 42 8
wb 0 0
year 0 0Maintenant les données ressemblent à ceci :
glimpse(police_europe)Rows: 546
Columns: 3
$ wb <chr> "ALB", "ALB", "ALB", "ALB", "ALB", "ALB",…
$ year <dbl> 2008, 2009, 2010, 2011, 2012, 2013, 2014,…
$ total_police_officers_number <dbl> 9588, 9229, 9670, 9723, 9728, 9477, 9625,…Calculer le nombre de policiers par habitant
Ce calcul a déjà été effectué par les auteurs de la base téléchargée. Toutefois, un examen attentif des données montre quelques choix un peu curieux, et nous incite à le refaire nous-même, par précaution.
Astuce
Le package wbstats donne accès aux données de la Banque mondiale, parmi lesquelles le nombre d’habitant, le PIB par tête, etc.
wb_path = here("data", "wb.rds")L’argument mrv donne le nombre de most recent values à requérir. L’argument gapfill = TRUE remplace les valeurs manquantes éventuelles par la valeur précédente la plus récente.
wbstats::wb_data(country = "countries_only",
indicator = c("gdp_per_capita" = "NY.GDP.PCAP.CD",
"population" = "SP.POP.TOTL"),
mrv = 15,
gapfill = TRUE) |>
write_rds(wb_path)wb = read_rds(wb_path) |>
mutate(country = str_replace(country, "Turkiye", "Turkey"),
wb = countrycode(country, origin = "country.name", destination = "wb")) %>%
rename(year = date) %>%
select(-iso2c, -iso3c, -country)police_europe_pcm = police_europe |>
filter(!is.na(total_police_officers_number),
year <= 2020) |>
filter(year == max(year, na.rm = TRUE), .by = wb) |>
left_join(wb, by = join_by(wb, year)) |>
mutate(policiers_pcm = total_police_officers_number / population * 100000) |>
mutate(pays = countrycode(wb, origin = "wb", destination = "country.name.fr"),
pays = if_else(wb == "MNE", "Monténégro", pays),
pays = if_else(wb == "MKD", "Macédoine du Nord", pays),
policiers_pcm = round(policiers_pcm)) |>
arrange(desc(policiers_pcm))Palmarès
Tableau
Note
La colonne “Année” indique la dernière année pour laquelle des données sont disponibles.
police_europe_pcm |>
select(pays, year, policiers_pcm) |>
rename(Pays = pays,
"Année" = year,
"Policiers pour 100 000 habitants" = policiers_pcm) |>
as_huxtable() |>
set_number_format(NA) |>
huxtable::theme_blue()| Pays | Année | Policiers pour 100 000 habitants |
|---|---|---|
| Monténégro | 2020 | 732 |
| Serbie | 2015 | 598 |
| Turquie | 2020 | 558 |
| Croatie | 2020 | 526 |
| Grèce | 2020 | 526 |
| Macédoine du Nord | 2017 | 514 |
| Bosnie-Herzégovine | 2020 | 487 |
| Kosovo | 2020 | 456 |
| Portugal | 2020 | 443 |
| Malte | 2020 | 435 |
| Bulgarie | 2020 | 421 |
| Italie | 2020 | 400 |
| Slovaquie | 2020 | 388 |
| Hongrie | 2020 | 385 |
| Albanie | 2020 | 382 |
| Tchéquie | 2020 | 375 |
| Chypre | 2020 | 371 |
| Espagne | 2020 | 370 |
| Autriche | 2020 | 358 |
| Irlande | 2020 | 356 |
| Slovénie | 2020 | 344 |
| Belgique | 2020 | 337 |
| Liechtenstein | 2020 | 324 |
| Luxembourg | 2020 | 323 |
| France | 2019 | 322 |
| Estonie | 2020 | 306 |
| Allemagne | 2020 | 301 |
| Pays-Bas | 2020 | 290 |
| Lituanie | 2020 | 281 |
| Pologne | 2020 | 258 |
| Roumanie | 2020 | 258 |
| Lettonie | 2020 | 234 |
| Royaume-Uni | 2016 | 224 |
| Suisse | 2020 | 216 |
| Suède | 2020 | 202 |
| Danemark | 2020 | 194 |
| Islande | 2020 | 175 |
| Norvège | 2014 | 167 |
| Finlande | 2020 | 136 |
Graphique
police_europe_pcm |>
mutate(pays = fct_reorder(pays, policiers_pcm)) |>
ggplot(aes(x = policiers_pcm, y = pays)) +
geom_bar(stat = "identity") +
labs(x = "Policiers pour 100 000 habitants",
y = "",
title = "Les Européens mieux protégés (?) au Sud et à l'Est") +
theme_minimal()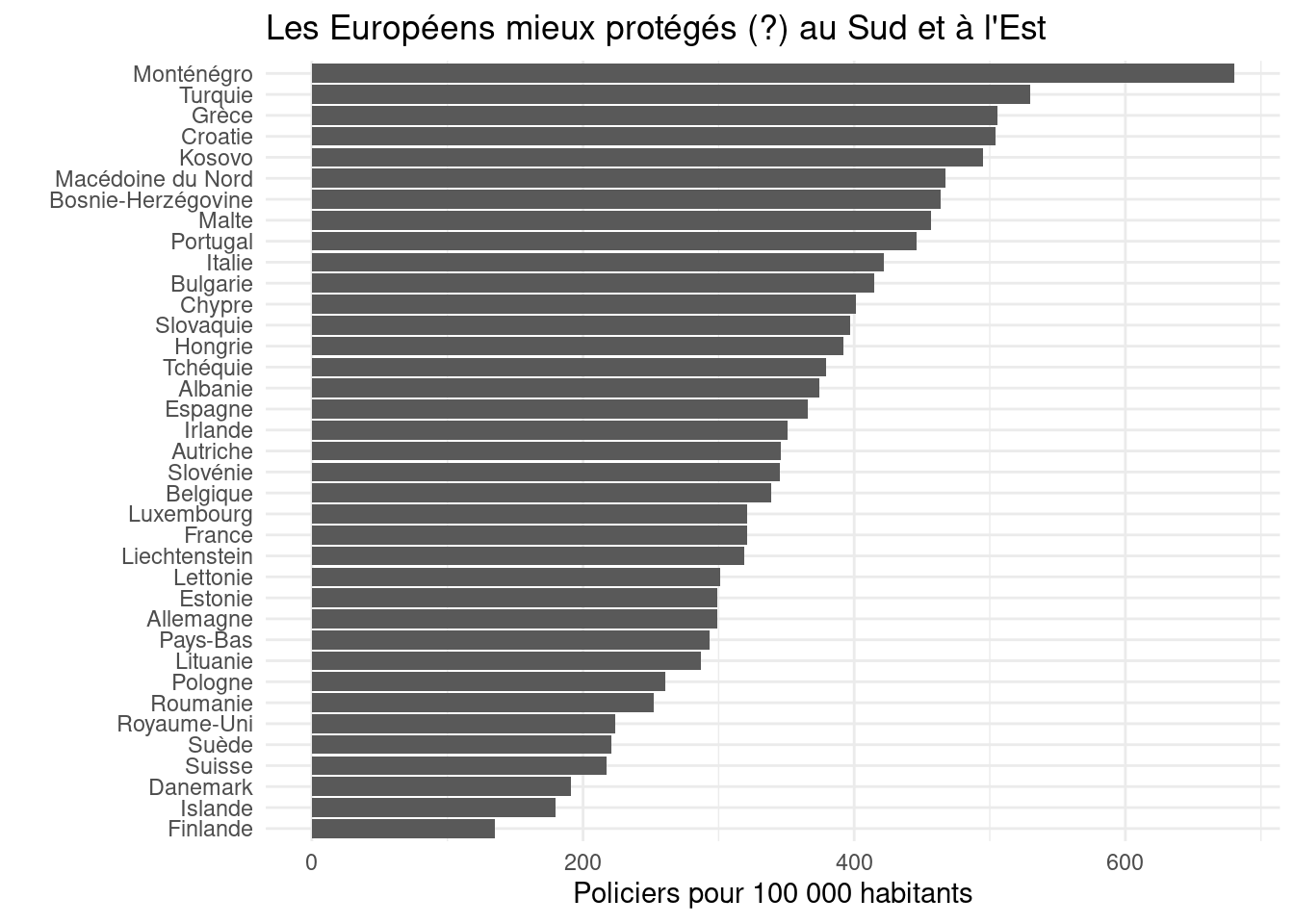
Citation
BibTeX
@online{boulakia2023,
author = {Boulakia, Théo and Mariot, Nicolas},
title = {Où y a-t-il le plus de policiers en Europe\,?},
date = {2023-06-25},
url = {https://l-attestation.github.io/exercices/policiers-europe/},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Boulakia, Théo, and Nicolas Mariot. 2023. “Où y a-t-il le plus de
policiers en Europe ?” June 25, 2023. https://l-attestation.github.io/exercices/policiers-europe/.